

Running a synthetic research startup, Ask Rally, I get asked sometimes to work on custom projects which we're happy to do, since it's always a fun learning experience and it gives us ideas for features to incorporate into the product. I talked to client recently who wanted to run a survey for 5,000 AI personas, compared to the 50-100 that a typical Rally user needs. Any process eventually hits problems at scale, so I thought I'd share what we found.
The Overly Agreeable Assistant
You've probably asked ChatGPT to simulate a customer's thoughts about your product. Makes sense, right? Instant feedback without the expense of actual market research. So why pay for Rally or do a custom project like this?
There's just one tiny problem: ChatGPT is trained to be helpful, not honest. Remember when OpenAI had to roll back their latest version for being too sycophantic? That's the thing - these systems aim to please, and you have no control as a user over the 'personality' of the model.

When I started working with AI personas, I discovered I got much more realistic responses from AI roleplaying as my customers when I went through the API, where I could set my own custom instructions. You can explicitly tell the model: "Don't be helpful. Be honest. Think like a skeptical consumer who has many options." or give it multiple examples of real life customer responses to emulate.
It's like the difference between asking your mom if your startup idea is good versus asking a stranger on the street. One loves you unconditionally; the other has no reason to protect your feelings.
But even with better instructions, you'll soon hit another limitation.
The Sample Size Problem
Let's say you write a script to generate 100 personas with varying demographics and preferences. This is much better, because you get a diversity of opinions from your AI crowd, and can zero in on what resonates. This is what the typical Rally customer gets and it's enough for 80% of use cases. So why did this client want 5,000 personas?
Say you're a mature brand with many different customer segments, and you want to drill into how a specific group responds - perhaps 6% of your audience works in construction and they have a strong preference for your product.
That sounds promising until you realize with 100 personas you're basing this insight on just 6 personas. Would you make business decisions based on feedback from 6 random people at a coffee shop? You can go and create another audience of 100 personas just for that demographic, but if you need to drill into multiple niches like this it can quickly get tiresome.
This is why scale matters. With 5,000 personas, that same 6% represents 300 simulated consumers. Suddenly you can:
- Dive deep into micro-segments with confidence
- Identify patterns that only emerge at scale
- Test hypotheses across diverse demographic groups
- Layer multiple segments onto the data until you find something juicy
- Drill into any other niche you want to investigate later
But as you ramp up production to create your 5,000 personas, you encounter a structural problem that makes your data scientist's eyes twitch.
The Consistency Challenge
When generating dozens or hundreds of personas, inconsistencies creep in faster than typos in a first draft. Each persona comes back in a slightly different format. Some have detailed preferences, others are sparse. Some use consistent terminology, others vary wildly.
I solved this by implementing Pydantic models to enforce structured outputs with the OpenAI API:
from pydantic import BaseModel, Field
from typing import Literal, List
class GenderEnum(str, Enum):
MALE = "Male"
FEMALE = "Female"
OTHER = "Other"
class IncomeEnum(str, Enum):
UNDER_25K = "Under $25,000"
INCOME_25K_50K = "$25,000-$49,999"
INCOME_50K_75K = "$50,000-$74,999"
INCOME_75K_100K = "$75,000-$99,999"
INCOME_100K_150K = "$100,000-$149,999"
INCOME_150K_200K = "$150,000-$199,999"
INCOME_200K_PLUS = "$200,000 or more"
class Persona(BaseModel):
age: int = Field(..., description="Age of the individual, expected range 24-44")
gender: GenderEnum = Field(..., description="Gender identity")
income: IncomeEnum = Field(..., description="Annual income")
education_level: str = Field(..., description="Highest level of education completed")
region: str = Field(..., description="Geographic region of residence")
# You can use these models with the OpenAI API like this:
# completion = client.chat.completions.create(
# model="gpt-4o",
# messages=[...],
# response_format=Persona
# )
With this approach, every persona follows the same structure with validated fields. No more parsing headaches or inconsistent data! Note that this is even better than the normal JSON mode parsing approach that OpenAI offers, it actually passes the full Pydantic schema directly so you don't get any retries (if I had to guess, they limit the tokens that the LLM is allowed to produce so that it can't predict anything other than a valid token).
But while the structure became consistent, I noticed something else disturbing in the data: the distribution of traits didn't always match reality. Having 90% of personas be high-income tech workers doesn't reflect any real consumer market unless you're selling $500 mechanical keyboards.
The Statistical Accuracy Problem
For results to be credible, personas need to collectively match known demographic distributions. If census data shows 18.9% of your target audience lives in the Northeast, your personas should mirror this - and not just superficially, but with appropriate correlations between attributes like income and education level. In this point it's really key to extract out of the client all of their assumptions and beliefs about their audience, both personally and internally at their company. If they have done a survey in the past that says 30% of their consumers are men, you better reflect that in your AI audience if you want them to treat your results with any kind of legitimacy. I call this process 'personification'.
To solve this I built an evaluator-optimizer pattern that:
- Checks the current distribution of all attributes across generated personas
- Compares it to target distributions from real market research
- Generates the next batch with emphasis on underrepresented traits
from typing import Dict, Any, List
import pandas as pd
def analyze_distribution(personas: List[Dict[str, Any]], target_distribution: Dict[str, Dict[str, float]]):
"""Analyze current distribution compared to target distribution"""
df = pd.DataFrame(personas)
results = {}
for attribute, targets in target_distribution.items():
if attribute in df.columns:
current_dist = df[attribute].value_counts(normalize=True).to_dict()
# Calculate gaps between current and target distribution
gaps = {}
for value, target_pct in targets.items():
current_pct = current_dist.get(value, 0.0) * 100
gaps[value] = {
"target": target_pct,
"current": current_pct,
"gap": target_pct - current_pct
}
results[attribute] = gaps
return results
With this feedback loop, each new batch of personas pushed the overall distribution closer to reality. As I ran the process I evaluated the distribution every 30 personas that were added, and then readjusted the prompt automatically to instruct the LLM what persona types to generate next (i.e. "Target: 50% Male, Actual 40% Male, generate more Male personas"). Elegant in theory, but when I ran the numbers, I realized another challenge. If each persona takes 3-5 seconds to generate, processing 5,000 would take 4-7 hours - and that's just for creation, not even running the survey yet!
The Processing Time Problem
I turned to async processing to speed things up. The idea was simple: don't wait for one persona to finish before starting the next, let them all generate simultaneously.
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI()
async def generate_persona(prompt, schema):
return await client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
response_format=schema
)
async def process_batch(prompts, schema):
tasks = []
for prompt in prompts:
tasks.append(generate_persona(prompt, schema))
return await asyncio.gather(*tasks)
This worked beautifully at first. My processing time plummeted and I felt like a genius.
Then the error messages started flooding my console. I'd hit rate limits, and adding retry logic actually made it worse. Suddenly I had an unknown number of API calls happening simultaneously, creating a cascade of retries that compounded the problem.
Rate limits were throttling my progress, but that wasn't even my biggest concern...
The Runaway Costs Problem
When I checked my usage dashboard after my initial testing, I nearly had a heart attack. Using the largest model for the full persona generation and survey process was costing approximately $12 per persona. Multiplied by 5,000 personas, I was looking at a potential $60,000 bill!
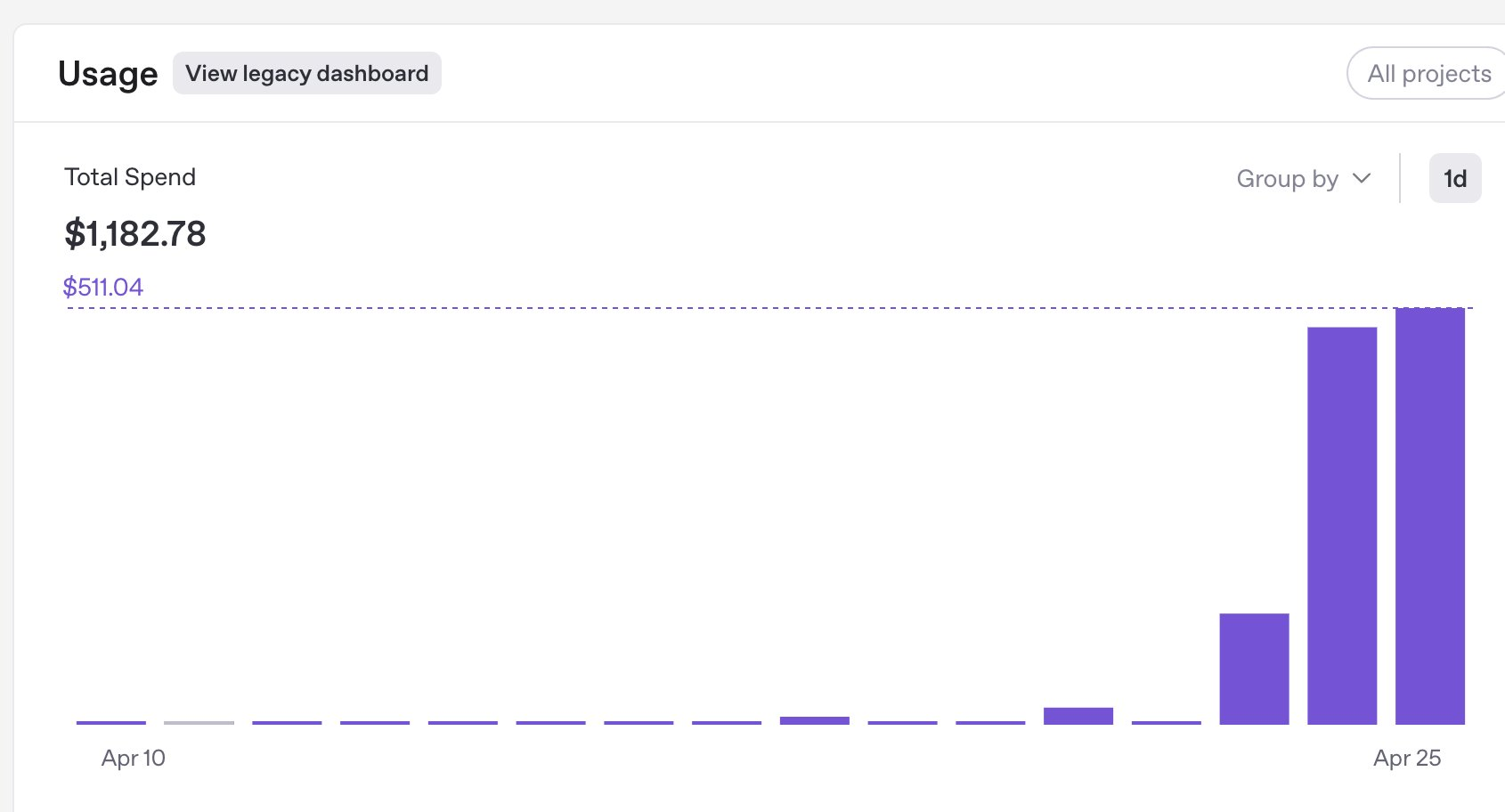
I immediately scaled down to smaller models for testing:
Model comparison:
- gpt-4o: ~$12.34
- gpt-4o-mini: ~$0.77 cents
- gpt-4.1-nano: ~$0.38 cents
That's a 97% cost reduction with the smallest model, with processing time actually improving! The outputs weren't quite as nuanced, but for testing purposes, it was a lifesaver. The quality didn't even degrade much with the smaller model, there was only a noticeable drop in reasoning ability.
For a large client who is accustomed to spending $60k on a survey, it might be worth it for the extra accuracy. AI gives you flexibility to ask more 'people' many more questions than you could in real life, so it doesn't necessarily follow that you would only do synthetic research to save cost. The main concern of this client was actually time: we were on a deadline and this survey was going to take days to run.
The API Call Overload Problem
My original design asked each survey question as a separate API call: pose a question, get an answer, add to context memory, ask the next question. With 20+ questions per survey, each persona required 20+ separate API calls.
Worse, each call processed the entire conversation history again, increasing token usage with every question. It was like having to reread an entire book every time you turned a page.
The simple solution was to use Pydantic models for entire survey sections:
# Example of a structure for batching multiple survey questions together
# This shows how we can ask for many responses at once
class SurveyResponse:
# Customer satisfaction (1-5 scale)
satisfaction_score: int
# Product feedback (multiple choice)
best_feature: str # Which feature they liked most
worst_feature: str # Which feature they liked least
# Purchase intent (yes/no/maybe)
would_purchase_again: str
# Price perception (too high, fair, too low)
price_perception: str
# Open feedback (free text)
additional_comments: str
This dramatically reduced API calls and costs. The final numbers per persona per survey ranged from 0.01 cents with the smallest model to 0.34 cents with the premium model. Processing times varied from 127 to 275 seconds depending on the model. The total survey costs us $100 each time we run it, which is much more manageable, and we can explore enriching these personas by feeding them 'media diets' to keep them current.
But just as I thought I was in the clear, I discovered yet another problem, and this one was completely avoidable.
The Data Management Disaster
After running several batches, I realized I had accidentally overwritten some survey results by reusing the same output folder name. Hours of processing and hundreds of API calls, wasted.
I rewrote the system to be idempotent, creating unique folders for each run and implementing recovery checkpoints:
import os
import json
import time
from typing import List, Dict, Any
def create_run_directory():
"""Create a unique directory for this survey run"""
timestamp = int(time.time())
run_dir = f"survey_run_{timestamp}"
os.makedirs(run_dir, exist_ok=True)
return run_dir
def save_checkpoint(run_dir: str, completed_ids: List[str]):
"""Save progress checkpoint"""
checkpoint_path = os.path.join(run_dir, "checkpoint.json")
with open(checkpoint_path, "w") as f:
json.dump({"completed_ids": completed_ids}, f)
def load_checkpoint(run_dir: str) -> List[str]:
"""Load previous progress if it exists"""
checkpoint_path = os.path.join(run_dir, "checkpoint.json")
if os.path.exists(checkpoint_path):
with open(checkpoint_path, "r") as f:
data = json.load(f)
return data.get("completed_ids", [])
return []
This meant I could start, stop, and resume the process at any time without losing data or duplicating work. It was like having save points in a video game - no matter what went wrong, I never had to restart from the beginning.
What I Learned
Looking back on this journey from a single ChatGPT persona to 5,000 statistically accurate simulated consumers, the key lessons were:
- Structure matters: Pydantic models ensure consistent, validated outputs
- Statistical accuracy is crucial: Match real demographic distributions or your results won't be credible
- Test with smaller models: Use budget models for development before scaling up
- Batch API calls: Send whole survey sections rather than individual questions
- Make everything idempotent: Design for failure recovery from the start
- Manage rate limits carefully: Async processing needs thoughtful rate limit handling
- Monitor costs religiously: API costs can spiral quickly at scale
With these lessons, you can create your own AI persona research at a fraction of the cost and time of traditional market research methods - just be prepared for the challenges that come with scale.
The coolest part? When it all works, you get insights from thousands of simulated consumers for pennies on the dollar compared to traditional market research. And while it's not perfect (nothing is), synthetic research can be around 85% accurate compared to human results it opens up possibilities for testing ideas at a scale that was previously impossible for most businesses.
Have you experimented with AI personas for market research? I'd love to hear about your experiences – each out to me directly on LinkedIn: https://www.linkedin.com/in/mjt145/

