

Most evals assume there's a right answer. You check if the output matches, you get a score, you move on. But what happens when the "right answer" is subjective? When you're trying to match a writing style, calibrate a persona, or generate creative work that needs to feel right rather than be right?
This is where I kept getting stuck. I've been writing about evals for a while now, and the hardest category has always been tasks where the only way to judge quality is with an LLM judge comparing against reference examples. There's no programmatic check. No exact-match metric. You're in vibes territory, and vibes don't hill climb.
I came up with an approach I'm calling the pairwise gold triad, and I think it's one of the most elegant eval patterns I've built. It solves a problem that drove me crazy for months, and it plugs directly into agentic optimization loops like Andrej Karpathy's autoresearch.
The Problem with Evaluator-Optimizer
Let me back up. Before the pairwise gold triad, my go-to architecture for subjective evals was the evaluator-optimizer pattern. I used this at AskRally for calibrating AI personas. The setup was essentially a modified Turing test: the persona would generate responses, an LLM judge would try to tell which output came from the real person and which came from the AI, and then we'd optimize the persona to trick the judge.
It worked, but it had a fatal flaw. Every time the persona got better at fooling the judge, the judge's accuracy dropped. So you'd retrain the judge. Then the persona's win rate dropped because the judge got smarter. So you'd retrain the persona. Back and forth, forever.
Someone asked me once how accurate the system was. I didn't have a good answer. Against the first judge? Near 100%. Against the tenth judge? About 50%, because the judge got way better. Every training run lived in its own little universe with its own judge, so no two runs were comparable. You couldn't point to a chart and say "we improved from X to Y," because X and Y were measured by different yardsticks.
How the Pairwise Gold Triad Works
The pairwise gold triad fixes this by keeping the judge constant. Here's the setup:
- Gold reference: A real example of what the output should look like (the ground truth, written by a human)
- Incumbent output: The output from your current best program or prompt
- Challenger output: The output from a new candidate program or prompt
The judge gets all three and answers one question: which output—incumbent or challenger—is more similar to the gold reference?
That's it. No scalar ratings, no rubrics, no "rate this from 1 to 5." Binary comparison against a concrete reference. The judge never changes. The gold references never change. The only thing that changes is the challenger.
Here's what this looks like in DSPy:
import dspy
class PairwiseGoldJudge(dspy.Signature):
"""Given a gold reference example and two candidate outputs, determine
which candidate is more similar to the gold reference in style,
tone, and content quality."""
gold_reference: str = dspy.InputField(
desc="The ground truth example written by a human"
)
incumbent_output: str = dspy.InputField(
desc="Output from the current best program"
)
challenger_output: str = dspy.InputField(
desc="Output from the new candidate program"
)
context: str = dspy.InputField(
desc="The input/prompt that generated both outputs"
)
winner: str = dspy.OutputField(
desc="Either 'incumbent' or 'challenger' — whichever output "
"is more similar to the gold reference"
)
reasoning: str = dspy.OutputField(
desc="Brief explanation of why the winner is more similar "
"to the gold reference"
)
def evaluate_challenger(
gold_examples: list[dict],
incumbent_program,
challenger_program,
judge_lm: str = "openai/gpt-4o",
) -> dict:
"""Run pairwise gold triad evaluation across a set of examples.
Args:
gold_examples: List of dicts with 'input' and 'gold_output' keys
incumbent_program: The current best DSPy program
challenger_program: The new candidate DSPy program
judge_lm: Model to use for judging
Returns:
Dict with win_rate, wins, losses, and per-example results
"""
judge = dspy.Predict(PairwiseGoldJudge)
wins = 0
results = []
with dspy.context(lm=dspy.LM(judge_lm)):
for example in gold_examples:
# Generate outputs from both programs
incumbent_out = incumbent_program(input=example["input"])
challenger_out = challenger_program(input=example["input"])
# Ask the judge which is closer to gold
verdict = judge(
gold_reference=example["gold_output"],
incumbent_output=incumbent_out.output,
challenger_output=challenger_out.output,
context=example["input"],
)
won = verdict.winner.strip().lower() == "challenger"
if won:
wins += 1
results.append({
"input": example["input"],
"gold": example["gold_output"],
"incumbent": incumbent_out.output,
"challenger": challenger_out.output,
"winner": verdict.winner,
"reasoning": verdict.reasoning,
})
win_rate = wins / len(gold_examples)
return {
"win_rate": win_rate,
"wins": wins,
"losses": len(gold_examples) - wins,
"total": len(gold_examples),
"results": results,
}
The evaluate_challenger function is the core loop. You pass in your gold examples, your current best program, and a challenger, and you get back a win rate. If the challenger wins more than 50% of the time, it becomes the new incumbent, and the bar goes up.
Why This Enables Hill Climbing (With the Ability to Jump Hills)
This is hill climbing, but with the ability to jump to the next hill. Let me explain what I mean by that.
In the evaluator-optimizer pattern, there's no stable landscape at all. You retrain the judge every few rounds, which is like redesigning the terrain mid-hike. There's no contour to grip onto. You can't tell if you're going up or down because the ground keeps shifting.
With the pairwise gold triad, the judge never changes and the gold references never change. That gives you a stable landscape—real contour. Every evaluation run is directly comparable to every other run. You can look at run 1 versus run 20 and say with confidence that the program improved, because they were measured by the same yardstick.
But here's what makes this more than ordinary hill climbing. When a challenger wins, it becomes the new incumbent, and now every future challenger has to beat a better sample. You're not stuck grinding on the same local optimum forever. Each time the incumbent gets replaced, you've jumped to the next hill. The bar goes up, but the landscape stays the same—same judge, same gold references, just a stronger comparison point.
The first time I ran this, my initial prompt had a win rate of about 75%—the challenger beat the incumbent 75% of the time. Not bad for the first attempt. But once that challenger became the new incumbent, the next three or four challengers failed. The bar had risen. The style was already much better, so incremental improvements were harder to find.
This is exactly what you want. Early wins are easy, and later wins are earned. You keep hill climbing on the same stable landscape, but every successful challenger resets the bar higher.
Building Test Cases: Fill in the Middle
The test cases matter. The pairwise gold triad gives you a robust evaluation framework, but you still need gold reference examples that actually test what you care about.
For my specific use case—building a skill that writes in my voice—I used a fill-in-the-middle approach. I had Claude go through my blog posts and, for any post with three or more paragraphs, pull out the middle paragraph. That extracted paragraph becomes the gold reference: what I actually wrote. The input is the surrounding context (the paragraphs before and after the gap), and the task is to fill in the missing middle paragraph. Here's an example:
Context before (paragraph A):
Running a synthetic research startup, Ask Rally, I get asked sometimes to work on custom projects which we're happy to do, since it's always a fun learning experience and it gives us ideas for features to incorporate into the product. I talked to client recently who wanted to run a survey for 5,000 AI personas, compared to the 50-100 that a typical Rally user needs. Any process eventually hits problems at scale, so I thought I'd share what we found.
Gold (paragraph B — what Mike actually wrote, the target):
You've probably asked ChatGPT to simulate a customer's thoughts about your product. Makes sense, right? Instant feedback without the expense of actual market research. So why pay for Rally or do a custom project like this?
Context after (paragraph C):
There's just one tiny problem: ChatGPT is trained to be helpful, not honest. Remember when OpenAI had to roll back their latest version for being too sycophantic? That's the thing - these systems aim to please, and you have no control as a user over the 'personality' of the model.
How it works: The model sees A and C and must produce B. The judge compares the model’s output to the gold (Mike’s actual paragraph) to measure how well it matches his style.
This is a surprisingly good test and it works on arbitrarily constructed datasets and formats – you don't have to care about what was written, only grab what came before and after, and compare the AI response to your gold answer. Writing style is most visible in longer passages, and the fill-in-the-middle format forces the program to match tone, vocabulary, and argument structure while staying coherent with the surrounding text. If the output reads like me, it'll be similar to what I actually wrote. If it reads like generic AI, the judge will catch it.
Plugging into Autoresearch
The pairwise gold triad was built to work with agentic optimization loops. Karpathy's autoresearch project automates the research cycle: an AI agent modifies code, runs an experiment, evaluates the result, and decides whether to keep the change. The agent runs dozens of experiments overnight while you sleep.
The evaluate_challenger function slots right into this pattern. The agent proposes a new prompt or program variation, the pairwise gold triad scores it against the incumbent, and if the challenger wins, it becomes the new baseline. The agent keeps iterating, and each morning you wake up to a log of experiments and a stronger program.
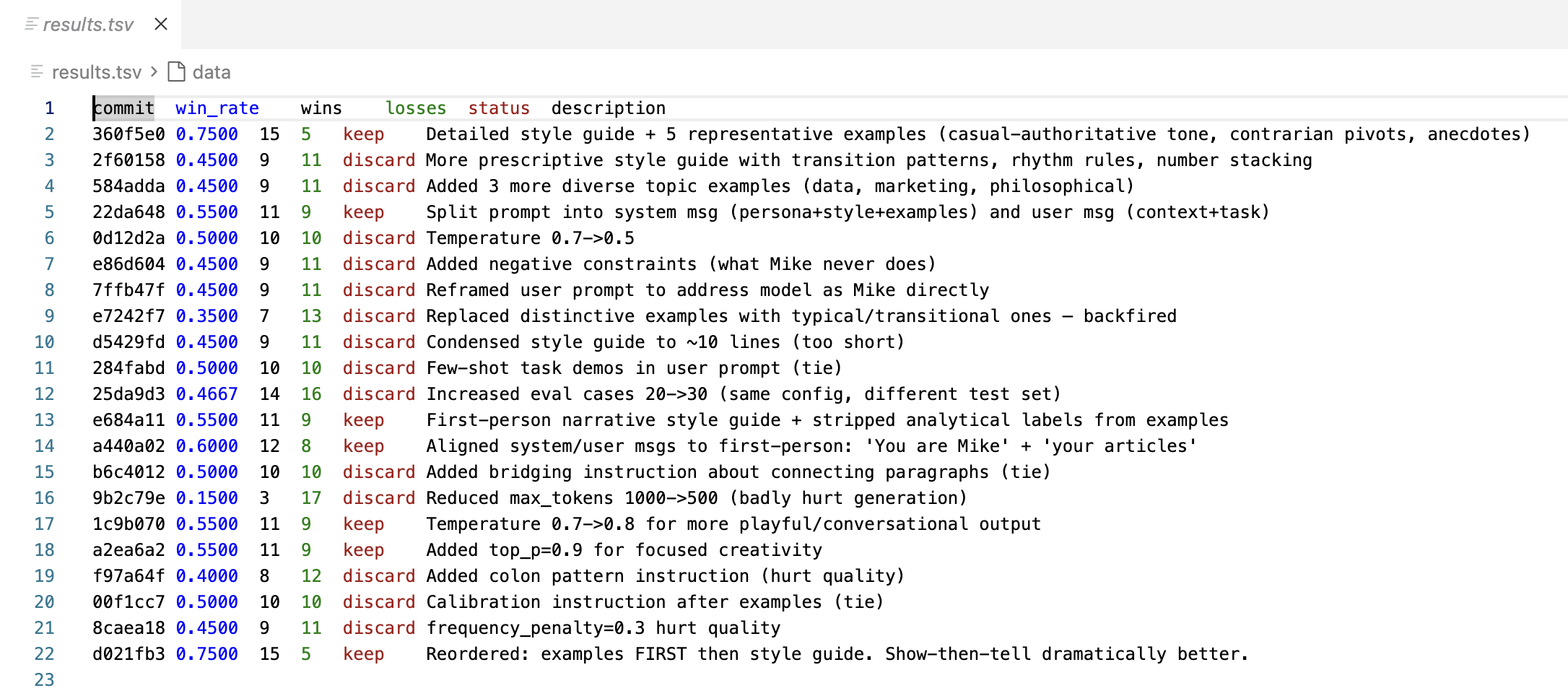
This combination—pairwise gold triad for the eval, autoresearch for the optimization loop—is how I'm approaching subjective tasks now. The eval is stable enough that the optimization loop can make meaningful progress, and the hill-climbing dynamic means the bar rises automatically.
When to Use This Pattern
The pairwise gold triad works best when:
- Your task is subjective. Style matching, persona calibration, creative generation—anywhere the "right answer" is a matter of judgment, not exact match.
- You have gold reference examples. You need real examples of what good looks like. These don't need to be perfect, but they need to be representative of the quality you're targeting.
- You want to iterate autonomously. The stable judge makes this compatible with agentic loops where no human is in the loop between runs.
It works less well for tasks with objective answers (use programmatic evals instead) or tasks where you have no reference examples at all (you'll need to build a dataset first—homework, I know).
The good news is that you don't need many gold examples to get started. I've been running this with about 20 fill-in-the-middle examples, and the signal is strong enough to distinguish genuine improvements from noise. Start small, and add more examples as you find edge cases where the judge gets confused.
.png)
