

For 99% of people, prompt engineering amounts to trying a few different prompts, manually reviewing the responses, and making changes until it seems like it's working.
To be honest, that's probably good enough if the task isn't that important, or if you're not likely to revisit the task again. The problem starts when you start relying on that prompt to do your work, perhaps even putting it into production in a tool or template, without some sort of system for testing what works (or doesn't).
This is a blind spot for AI engineers because they get excited by fine-tuning or evaluating different models, rather than writing better prompts. For example, did you know the default summarization prompt langchain uses under the hood is just "`Write a concise summary of the following: <text>`"? The Twitter gurus you see sharing ChatGPT templates all fail in the other direction, writing prompts as if they are some ancient wizard casting spells for conjuring up desired behavior from a malevolent AI.
This notion that AI is magic is harmful, because it implies these systems can’t be controlled or aligned towards our goals. Imagine if we gave up on all of management science, economics, and psychology just because humans are unpredictable! The great benefit of working with artificial intelligence over human intelligence is that it’s far easier to run experiments: they never get tired of hearing the same question 50 times, and retain no memory in between trials.
True prompt engineering is scientifically testing and learning which inputs lead to useful or desired outputs, reliably at scale. It may be overkill for most throwaway tasks, but for prompts you plan to use hundreds or thousands of times, it's essential. The process looks like this:
1. Metrics – Establish how you'll measure the performance of the responses from the AI.
2. Hypothesis – Design one or more prompts that may work, based on the latest research.
3. Testing – Generate responses for your different prompts against multiple test cases.
4. Analysis – Evaluate the performance of your prompts and use them to inform the next test.
If you're technical and you want to follow along in code, here's the notebook and text examples I used for this experiment: https://github.com/hammer-mt/prompt_optimization_blog
Example Task
Before I started working full time on prompt engineering, much of my time was spent writing blogs on technical marketing topics. I noticed early on while experimenting with AI content writing, that ChatGPT’s informative and inoffensive tone was easy to recognize, and therefore I spent a bunch of time figuring out a prompt for rewriting text in my own writing style. The prompt that I have works well enough, and I got there through crude trial and error:
```Rewrite the article in the following style:
- Concise and to the point
- Professional and knowledgeable tone
- Relatable and accessible language
- Uses storytelling to convey ideas
- Relies on examples and case studies
- Mixes personal anecdotes with industry insights
- Provides actionable advice and tips
- Uses subheadings and bullet points for easy readability```
Now that I’m using this prompt more often, and I’m finding no noticeable improvement from continued trial and error, it’s the right time to level up to prompt optimization. If I can A/B test different approaches with an objective measure of performance, I can be more certain my changes are helping rather than harming results.
1. Metrics
The first thing we need to decide on is how we’re going to measure performance. When we’re just running the prompt 2-3 times we can manually review the responses, but that gets tedious and unreliable when we’re running it 20-30 times.
The key is defining a programmatic definition of success, something we can run in a script to compare the relative performance of multiple samples at once. The open-source library Langchain has a number of standard evaluators for you to use, including the capacity for you to build and apply your own.
In this case we’ll use the `embedding_distance` evaluator which gives us a measure of similarity between two sets of text (lower is similar, higher is different). For this experiment I asked GPT-4 “Explain value based pricing”, which is a topic I have written about. We’ll use this as the Input text, and then we’ll ask GPT-4 to rewrite it in my style. I personally rewrote that text and saved it as a reference example, or ground truth, which we’ll compare using the embedding distance.
2. Hypothesis
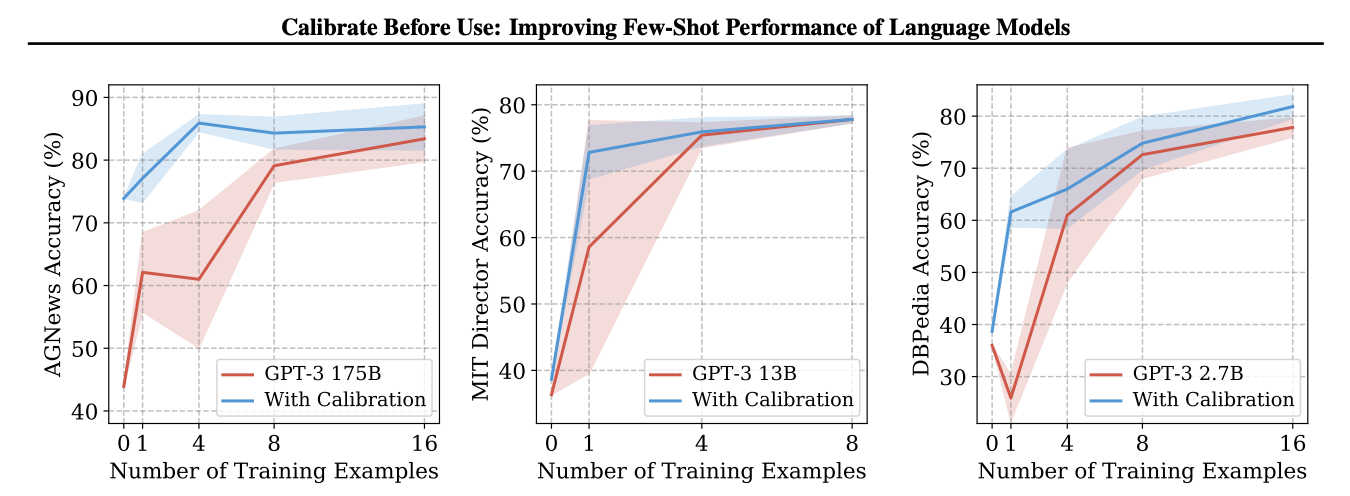
One commonly used prompt engineering technique is few-shot prompting, meaning providing a number of examples of the task being done correctly, inserted into the prompt. This is one of my five principles of prompting, and is always one of the first things I try. The evidence in the literature (Lilian Weng provides a good summary) shows that few-shot prompting can have a huge impact on performance, although the results can be unstable and biased in some cases.
We don’t just want to start inserting example text into our prompts and blindly trusting that it’ll help. Adding examples comes at a cost, both in terms of extra tokens, and the cost of finding and inserting relevant examples each time we want to use this prompt. If we’re guaranteed a step-change in performance it’s worth it, but if the difference is less than 5%, or it causes instability or bias in our results, we’ll stick with what we already have.
In this case, I’ll take some of my writing from another post to provide as an example, and insert that alongside the existing prompt. The prompt in this case goes in the System message (a place for giving instructions on how the AI should perform), and we’ll add the writing example as the first message in the queue, with a follow up message formatted as an AI response, in order to ‘trick’ into thinking the user submitted and it responded already:
```System: You will be provided with the sample text.
Your task is to rewrite the text into a different writing style.
The writing style is:
- Concise and to the point
- Professional and knowledgeable tone
- Relatable and accessible language
- Uses storytelling to convey ideas
- Relies on examples and case studies
- Mixes personal anecdotes with industry insights
- Provides actionable advice and tips
- Uses subheadings and bullet points for easy readability
Human: Here is an example of the writing style:
{writing_style}
AI: Thank you for the example of the writing style. Now please provide the sample text.
Human: {input_text}```
3. Testing
Now we’re ready to run the test and generate our samples. Rather than just running both prompts once and comparing the results, we’re going to run them 20 times each. That will give us a better understanding of how reliable the results are at scale, and how often they deviate significantly from our reference text. We can then average the score that we get from our evaluation metric, and see overall if one prompt is better than the other.
This will already be far better than what the average ChatGPT guru does, because it’s more systematic and will surface problems that would only appear at scale. However, this is still far from scientific, and we’d want to see how well the prompts do across multiple test cases if we were putting it into production. The prompt might do well on this value-based pricing example, but fail miserably on other topics or in other scenarios. You’d also want to test different methods for retrieving the relevant example text, for example querying a vector database, because that can make a big difference.
In my experiment I’m using Langchain to initialize the LLM and to create the prompt template, as it minimizes the potential for errors, and makes my code more reusable. If we want to swap out GPT-4 for a different model, or use a different evaluation metric, we only need to change a handful of lines. Langchain also comes with all the necessary retry logic, and using `tracing_v2_enabled` it’s simple to log the results to a file or to a platform like LangSmith for further analysis.
4. Analysis
In measuring the results, what we’re looking for is how close we can get to the text that I personally rewrote. If we can get closer to my actual writing style when translating AI-generated text, it’ll save me a lot of time rewriting that text manually. When we’re comparing embedding distance the lower the better, so we’re looking for what prompt gets us a consistently lower score. We should also be on the lookout for variance: a prompt that scores well on average may still be a problem if on occasion it goes disastrously off course.
Even just running my first prompt itself 20 times is revealing, because we can see just how often it’s off the mark. The embedding difference on average is 0.65, but it ranges from as low as 0.05 (good), to as high as 0.096 (bad). Knowing this variance we can build in more protection against anomalous results, for example by not just running it once but taking the best of three runs. As we have a programmatic definition of success, embedding distance, we can calculate that on the fly in order to automatically select the ‘best’ of each batch.
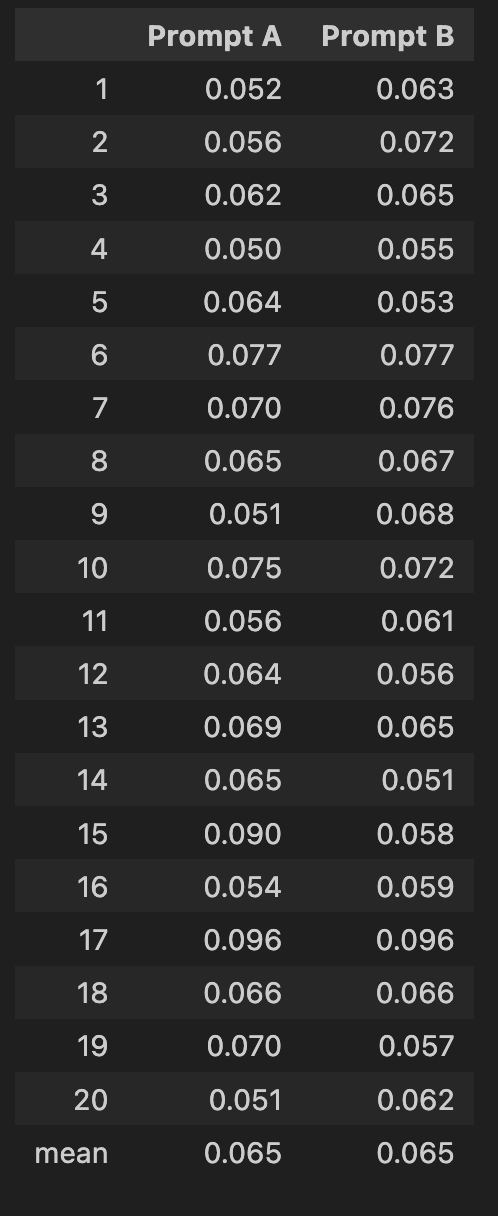
The end result of the A/B test is that the change to the prompt didn’t perform any better: the average distance was exactly the same at 0.065. Even though it can be disappointing to get a negative test result, this is actually a huge win: we might have blindly added these examples to our prompt going forward, costing us an extra ~500 tokens per example for no gain. At current GPT-4 pricing that’s only 1.5 cents per run, but if this is being run thousands of times a day as part of a product, that cost can quickly add up to hundreds of dollars a month. It also greatly simplifies our app design knowing we don’t have to ask the user for samples of their other writing, making for a better user experience.
From here we can go in a different direction for our next test, for example:
- Discovering different ways to define our writing style.
- Trying another technique from the scientific literature, like self-evaluation.
- Attempt to replicate these results using GPT-3.5-turbo, which is 10x cheaper and less rate-limited.
- Conduct a manual rating evaluation, to sense check that embedding distance is reliable.
- Define a different evaluation metric, for example asking GPT-4 to rate the similarity.
- Dial up the number of examples to 3, 5, or 10 see what happens.
- Use a model with a larger context window and throw 100 examples in there.
- Fine-tuning a model based on our data (which tends to beat prompt engineering at ~100 examples).
Whatever direction we decide to take, we have now established what ‘good’ performance looks like, and have evidence we can provide to our boss or other stakeholders to justify our decisions. This is the difference between prompt engineering and blind prompting, and as the field of AI professionalism, this will become standard practice. In the meantime however, there’s a tonne of low-hanging fruit to pick, because almost nobody is being rigorous with their prompts!
Update: I ran further experiments on this prompt which you might be interested in. Read the post "AI Writing Style Experiment"

